做量化首先要解决数据来源的问题。
数据有两类,一类的价量数据,就是通过我们说的”开盘价“,”收盘价“,‘”最高价’,“最低价”和“成交量”,即“OHLCV”。这些数据是时间序列数据,最常见的是日频数据。
另外,像股票还有基本面数据,常见的财务三大报表和PE/PB这样的指标。
偏技术分析类的策略,量价数据就够了。
从学习量化入门的角度,日频的量价数据就足够了。
高质量的金融一般都比较贵,好在python生态有开源包akshare,可以提供以上数据。
金融数据获取与处理
AKShare是一个基于Python的开源财经数据接口库,它提供了一系列工具,用于实现对股票、期货、期权、基金、外汇、债券、指数、加密货币等金融产品的基本面数据、实时和历史行情数据、衍生数据的采集、清洗和落地。
官网地址:https://akshare.akfamily.xyz/
数据字典地址:https://akshare.akfamily.xyz/data/index.html
这里有详细的数据接口使用说明。
另外,它是完全免费的。
我们以下载股票日线数据为例,讲解akshare的数据获取:
在“数据字典“下找到”A股>历史行情数据“。
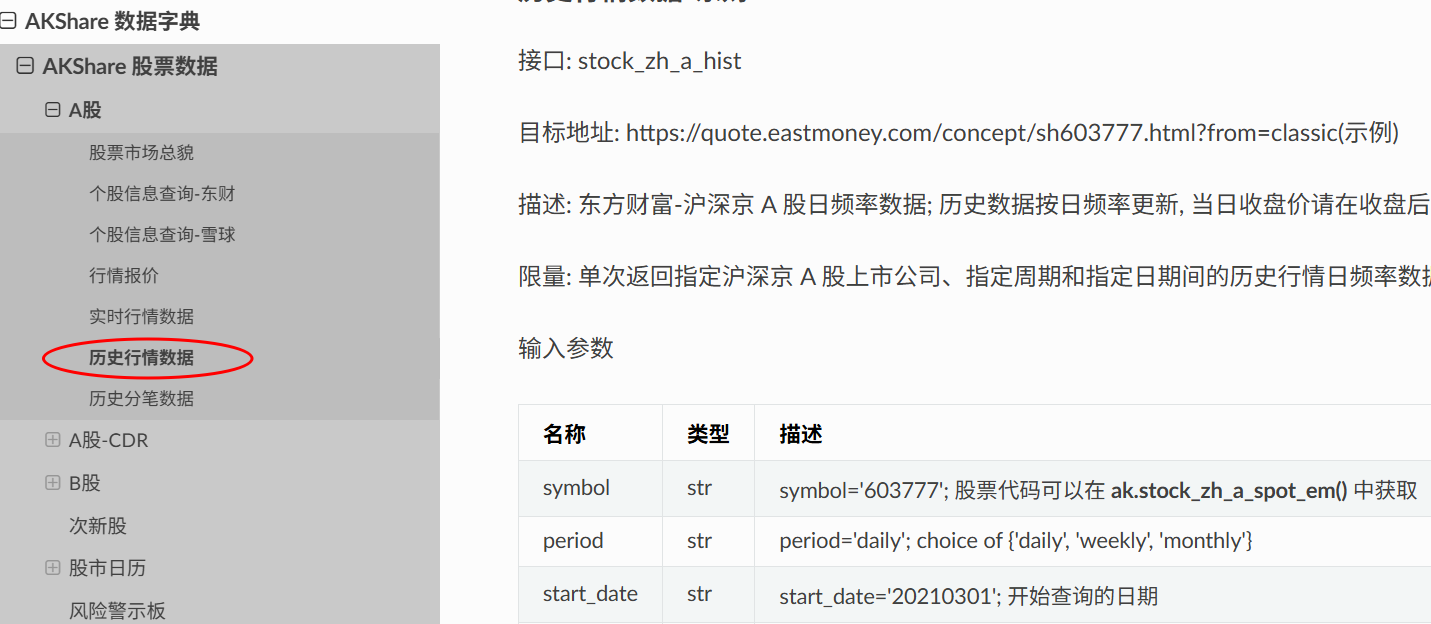
这里需要注意一下”复权“的概念,股票背后的东西会分红、拆股这样的操作,导致股份会出现跳跃式变化。而在回测过程中,我们需要把这些因素还原回去,就叫”复权“。
回测中通常使用后复权,因此我们下载后复权数据。
akshare最大的好处是,它可以指定下载复权数据。
start_date和end_date均不填的情况下,就是下载全量数据,而且是后复权的(直观来说,后复权的数据,会比真实的股票价值高,因为它把分红的要加回去)。
下载回来的数据,是中文表头,可以通过rename来修改:
inpace表示在当前的df上修改,columns=字典类型的数值对即可。
然后如前文to_csv直接保存到本地备用即可。
其余的数据下载大同小异,大家直接在官网看相应的文档说明即可。
金融数据处理
pandas库介绍
Pandas 是一个开源的数据分析和操作库。它提供了高性能、易用的数据结构和数据分析工具。
Pandas 提供了两种主要的数据结构,DataFrame 和 Series。DataFrame 是一个二维标签化数据结构(类似于 Excel 表格),而 Series 是一维数组。
pandas功能强大,可以说一个可编程操作的excel。
-
数据操作:支持数据过滤、分组、聚合和转换等操作。
-
数据清洗:提供工具处理缺失数据、数据过滤和数据替换。
-
时间序列分析:支持时间序列数据的高级处理,包括时间索引、频率转换等。
-
数据合并:支持数据连接、合并和 join 操作。
-
数据重塑:提供数据透视表、交叉表和数据重塑功能。
-
数据输入输出:支持多种格式的数据输入输出,如 CSV、Excel、JSON。
Pandas 是 Python 数据科学领域的核心库之一,广泛用于数据挖掘、数据清洗、数据分析和数据可视化。它的设计使得处理大型数据集变得简单高效,是数据科学家和分析师的重要工具。因此,它在量化投资里应用非常广,它的Dataframe是很多量化回测系统的基础数据结构。
python量化投资里,主要使用pandas来加载、处理数据,计算指标等。
pandas安装比较简单:
pip install pandas
量化第一步:从csv里加载数据
一个CSV文件中读取股票数据,将日期列设置为索引,然后对数据进行排序和日期格式转换,最后返回处理后的数据集。
import pandas as pd
%matplotlib inline
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
def get_data(symbol):
data = pd.read_csv('data/{}.csv'.format(symbol))
data['date'] = data['date'].apply(lambda x: str(x))
data.set_index('date', inplace=True)
data.sort_index(ascending=True, inplace=True)
data.index = pd.to_datetime(data.index)
return data
df = get_data('159915.SZ')
df
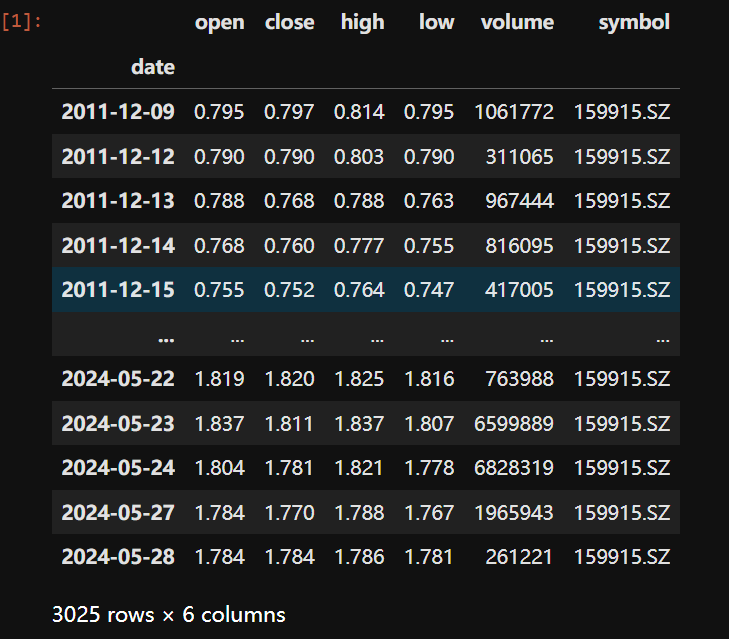
从前文保存的文件里,读取数据,将日期列转换为字符串类型,设置为索引,然后对索引进行排序,并将索引转换为datetime对象,最后返回这个处理后的DataFrame。
data = pd.read_csv('data/{}.csv'.format(symbol))
使用pandas库的read_csv函数来读取一个CSV文件。文件存放在名为data的目录下。读取的数据被存储在变量data中。
data['date'] = data['date'].apply(lambda x: str(x))
使用apply函数将date列中的每个元素转换为字符串类型。这一步是csv会把日期字段当成数字所有需要先转换成字符串。
lambda x: str(x)是一个匿名函数,它接受一个参数x并返回x的字符串表示。
data.set_index('date', inplace=True)
这行代码将data中的date列设置为索引。inplace=True参数表示这个操作会直接在原始的data变量上进行修改,而不是创建一个新的DataFrame。
data.sort_index(ascending=True, inplace=True)
对data DataFrame按照索引(即日期)进行排序。ascending=True表示按照升序排序,inplace=True同样表示这个操作会直接在原始的data变量上进行修改。
data.index = pd.to_datetime(data.index)
将索引(日期)转换为pandas的datetime对象,这样可以方便地进行日期相关的操作。pd.to_datetime函数用于转换日期格式。
以上是量化投资金融数据处理中最常用的操作,从csv加载数据,对数据进行预数据,排序。
量化第二步:计算指标
指标是指通过基础价量数据(OHLCV),衍生计算得到指标数据,比如动量,各种技术指标如均线,MACD, KDJ等。
咱们今天的策略,需要使用的指标是动量,动量的定义就是```
“过去N天的收益率”
。
pandas的series支持pct_change(N)来计算收益率。
还可以通过如下函数来计算:
factor = df['close'].pct_change(20)
factor
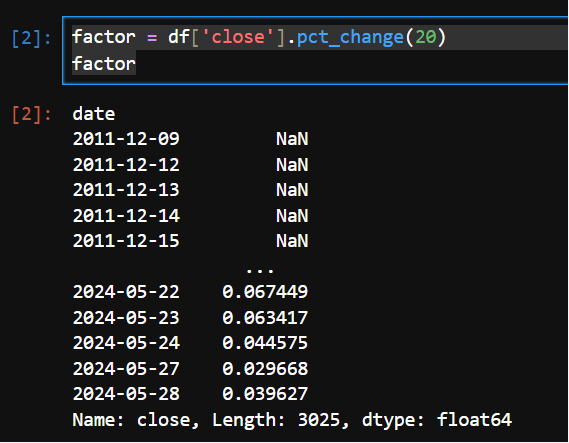
这里使用序列的向量化计算,shift是向下移动多少个位置,相当于是N天前的价值,当前的收盘价/20天前的收益价 减去1 ,也就是过去20天的收益率。
pandas的功能非常强大,时间序列的计算函数非常丰富,这个在策略开发过程中,可以查询相应的文档。
量化第三步:生成信号
我们的交易规则是:
20天动量 大于 0.08时买入
20天动量 小于0时清仓
我们使用了numpy和pandas库来创建一个新的signal序列。
import numpy as np
signal = np.where(factor>0.08,1,np.nan)
signal = np.where(factor<0,0,signal)
signal = pd.Series(signal,df.index)
signal = signal.ffill()
signal = signal.fillna(0)
signal
下面是每一步的详细解释:
signal = np.where(factor>0.08,1,np.nan)
使用numpy的where函数来创建一个新的数组。
where函数的第一个参数是一个条件表达式,这里检查factor数组中的每个元素是否大于0.08。如果条件为真,则在相应的位置放置1,否则放置np.nan(即不是数字的值)。
signal = np.where(factor<0,0,signal)
再次使用numpy的where函数,这次检查factor数组中的每个元素是否小于0。如果是,则在signal数组的相应位置放置0,否则保持signal数组的当前值(即上一步中设置的值)。
signal = pd.Series(signal, df.index)
将signal数组转换为pandas的Series对象,并使用df.index作为这个序列的索引。
signal = signal.ffill()
使用ffill方法对signal序列进行前向填充。这意味着所有的NaN值将被前一个非NaN值替换。如果序列开始处就是NaN,则该NaN保持不变。
这里为何要调用ffill前向填充,仔细想一下,在于0.08的标记为1,小于0的标记为0, 还有(0-0.08)之间的现在值是Nan,前向填充意味着,与上一个值保持一致,也就是说前面是1,后面就填为1,是0就填成零。在投资里就叫“保持持仓状态不变“。
signal = signal.fillna(0)
使用fillna方法将signal序列中剩余的NaN值替换为0。
这一段理解了,后面的策略就非常简单了。
量化第四步:生成策略
daily_returns = df['close'].pct_change()
strategy_returns = signal.shift(1) * daily_returns
# 计算累积收益
portfolio_value = (1 + strategy_returns).cumprod()
portfolio_value
曲线绘制出来,就是10年8倍的效果。
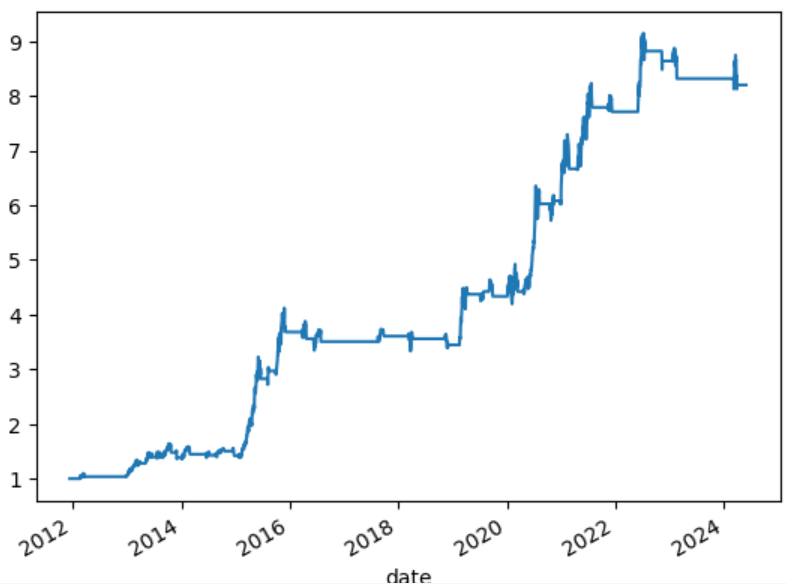
量化第五步:绩效评估
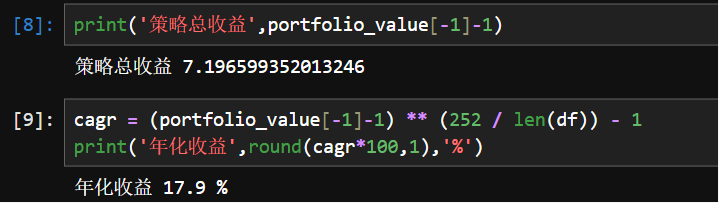
portfolio_value是策略终值,初始值是1,那么收益率就是 (终值-初始值)/初始值。
总收益到年化收益的计算,这里涉及一个复利的概念。
**(252 / len(df)):这里,252通常代表一年中的交易日数量,len(df)是数据集中的总交易日数量。252/交易日=年数的倒数,**是开方运算,这个操作将累积收益率转换为年化收益率。
小结
我们使用akshare分别获取创业板指数的历史日频价量数据,并保存到csv中。
从csv中加载数据,并做适当的预处理。
通过pandas(numpy),计算出收盘价的20日动量,同时按交易规则计算交易信号。
依照交易信号,计算出策略的收益率序列。
通过收益率序列,计算出策略最终的累计收益,然后计算出策略的年化收益。
中间过程通过pandas的plot函数实现可视化。
以上,我们完成了使用pandas从数据加载到策略实现过程,完成了创业板动量择时策略,年化17.9%,是一个还不错的策略。